This chapter is for advanced users/admins.
Diagnostic can be made on different levels. All levels are described in this chapter.

Introduction
| Level | |
|---|---|
Configuration
|
It relates to all configuration items in the plugin, such as Connection, Contract, Field Mapping Templates. That is the first level to check.
|
Synchronization
|
At this level you can diagnose data synchronization (issues, fields, comments, attachments). |
Infrastructure
|
Infrastructure can be more difficult to diagnose because of many external factors that can interfere with synchronization. That level refers to SSO, HTTP accelerators, proxies, etc. Unresolved problems from other levels may lead to infrastructure. |
Architecture
Deeper understanding of the plugin architecture may be helpful to resolve problems.
The plugin uses two queues to handle messages (IN, OUT). Each JIRA instance has these queues.
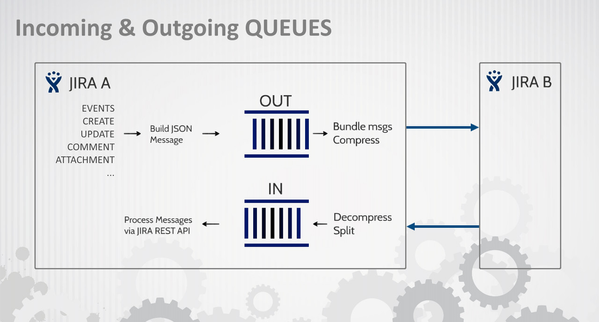
![]() Please, read below all marks carefully. This is quite low level introduction which understanding may be crucial to resolve some problems.
Please, read below all marks carefully. This is quite low level introduction which understanding may be crucial to resolve some problems.
- Message are stored in queues.
- Messages are flush after some period of time (see Schedulers).
- There are several services and each service may have several tasks in sequence. For example OutgoingService do following:
- Process outgoing messages in NEW status (message types: Create, Update, Comment)
- Process outgoing messages in RETRY status (message types: Create, Update, Comment)
- Process outgoing messages in RETRY status (message types: Attachment)
- Process outgoing messages in NEW status (message types: Attachment)
- So you can image that single flush may not be able to process all data-synchronization at once.
- Each service can execute in different order each time (depending on cron and execution duration).
- Each service has some tasks that change message statuses which need to wait for next service execution to process further.
- Communication depends on execution from both JIRAs. Flushing local queues is not enough to make synchronization happen. They need to be flushed on remote JIRA too.
- You can make flush faster from Synchronization web panel on issue (described below).
- Messages (and services) have two main categories:
- Data (fields, comments, attachments)
- Confirmation / Response (only for acknowledge)
- Queues are in JIRA DB. You can browse them with right tool (SQLDeveloper, Heidi, MySQL Query Browser, etc.).
- Communication is made using HTTP protocol. You can sniff this communication with tools like HTTPNetworkSniffer.
- Changes on issues are in 90% made using JIRA REST API. However this API is called from local JIRA (not remote).
So this is internal HTTP communication. - There are different strategies to handle: create-update, comments, attachments. So HTTP messages may differ.
- Data format is JSON.
Preinstalled Components
During installation plugin create custom fields:
Under the hood there are 7 services responsible for synchronization task:
- Outgoing Job - it is responsible for sending changes data to remote JIRA,
- Incoming Job - it is responsible for handling data receipt from remote JIRA,
- Outgoing Response Job - responsible for sending changes confirmation to JIRA which started data synchronization,
- Incoming Response Job - deals with incoming responses (mark data as synchronized),
- Archivization Job - move all synchronization data marked as done to archive,
- Pull Job - when JIRA is behind firewall(connection is in passive mode) and is not able to send synchronization data to remote instance, pull job in remote JIRA fetch data and performs synchronization,
- Pull Response Job - when JIRA is behind firewall(connection is in passive mode), this job in remote instance fetch all acknowledge information(it's similar to Outgoing Response Job, but works only when connection is in passive mode).
You can decide how often jobs run, to do that set whatever Cron expression you like in general configuration of the synchronizer.
See also Schedulers
Configuration Level
Connection
|
Connection setup has a test which should be executed in first place (it may not be successful until the remote JIRA does not have corresponding connection set).
If you get negative test over and over:
The plugin uses connection to synchronize configuration. Configuration synchronization can be forced on contract level:
 If you see warning
|
Contract
|
There is a lot of configuration on contract page. There are validators that play a gatekeeper role for contract consistency. Nevertheless, there may be some backdoor that, if reported will be continuously improved.
To make a contract valid you need to bind it with remote contract. So contract always works in pairs (local-remote).
In this example we have local contract named Default contract that binds to remote contract Default .
Field Mapping is defined in two stages (see below for more) and it requires contract bind to complete. Technical user permission! It is very important to keep in mind to extend Technical user permission (the one from connection) if new contracts are added for new projects. Verify permission on different levels:
You can browse contract's queue logs by pressing log icon:
More about Log Browser you can find below.
|
Fields Mapping
|
There are some validators implemented around Field Mapping (select only relevant remote field type for your local one, provide local field name, etc.). In current (and upcoming) plugin versions we try to avoid adding too much restrictions on custom fields type mapping. There is a lot of custom fields provider on Atlassian Marketplace we cannot handle and some are with very sophisticated API. However, there is a chance that they support JIRA REST API and can be used with IssueSYNC plugin. We give you a possibility to try it for your own.
In some cases you can find an error message in the log file that refer to Field Mapping problem: ERROR Unsupported field type detected. Field Status (status) has no field mapper! That means the field 'status' is not supported and cannot be synchronized. (For that particular field see Workflow Synchronization.)
However this error: {"errorMessages":[],"errors":{"project":"project is required"}}
may have source in wrong Field Mapping (Remote Field names). |


Synchronization Level
Synchronization |
There is a web panel on issues that have a Contract set. This panel can be disabled in general plugin configuration.
Panel sections:
Show Logs opens Log Browser in context of given issue (for more see Log Browser).
|
Log Browser |
Log Browser is available in Administration -> Add-ons -> IssueSYNC -> Logs Browser
|
Log Files
|
JIRA has two folders with log files:
In the first one, the plugin creates intenso-synchronizer.log file with most of its logs. In case the file size will reach 20 MB intenso-synchronize.log.1 will be created. After a while old log files should be removed.
Reading logs can be difficult because it contains error codes. For example: 2015-09-22 11:12:24|INFO |2|syn001|(SCHEDULED)| syn001 is a code that translates to "Archivization task was run!" (SCHEDULED)
Complete codes list can be found in plugin jar (downloaded from marketplace or from your JIRA_HOME/plugins/installed_plugins directory) in file synchronizer-extended-logger.properties
|
Database |
Queues can be browsed directly in database (use your favorite DB client):
There is also a log queue that contains more details about communication:
QueueIn Statuses:
QueueOut Statuses:
Few words about the sync flow
|
Disabled Contract
|
Contract can be disabled either one or both ways. Here are some rules that should apply SINCE V0.8.1
|


Infrastructure
HTTP / Firewall
|
In case of connection problem, one thing to check are firewall rules. Communication can be blocked either by local or remote environment. Firewall should have exceptions that allow to pass HTTP communication on JIRA server port. For more details please check documentation for your firewall software.
|
HTTPS / SSL
|
If one JIRA communicates with another one via SSL protocol it is required that server has a valid certificate installed. You can use this plugin to do that https://marketplace.atlassian.com/plugins/com.atlassian.jira.plugin.jirasslplugin/server/versionhistory This is required because it is server-server communication rather than client-server.
|
cURL
|
Use cURL tool to check connection problems.
Test #1 - Check if JIRA can make a call to itself.
Execute cURL command like this: curl -D- -u techUser:techUserPassword -X POST --data @test.json -H "Content-Type: application/json" https://my.jira.domain/rest/api/2/issue Where:
Example test.json file: {
"fields": {
"project":
{
"key": "DEMO"
},
"summary": "Issue created from REST.",
"issuetype": {
"name": "Bug"
}
}
}
This is create issue message (see JIRA REST API for more). You may need to customize this message to correspond your projects, issue types, required fields on create issue screen. Expected result: HTTP/1.1 201 Created
Server: Apache-Coyote/1.1
X-AREQUESTID: 753x265x1
X-ASEN: SEN-L5760827
Set-Cookie: JSESSIONID=4E76FC9C1CF6DC2968E99F9FCC212C2B; Path=/; HttpOnly
X-Seraph-LoginReason: OK
Set-Cookie: atlassian.xsrf.token=B4ZU-DJPZ-5KS0-30HD|2c3e821cadc54f8863793fd9e0f7698797800b37|lin; Path=/
X-ASESSIONID: 1sxm55y
X-AUSERNAME: admin
Cache-Control: no-cache, no-store, no-transform
X-Content-Type-Options: nosniff
Content-Type: application/json;charset=UTF-8
Transfer-Encoding: chunked
Date: Mon, 21 Sep 2015 10:33:25 GMT
{"id":"10300","key":"DEMO-17","self":"https://my.jira.domain/rest/api/2/issue/10300"}
That test's result means:
That result means the test has FAILED: curl: (6) Could not resolve host: host-from-baseURL
Test #2 - Check if local JIRA can make a call to remote JIRA. Execute similar cURL command like int Test#1 but
This test is only for Active (see Connection) JIRA instance. The passive probably does not have access to the network.
|
HTTP Accelerators |
Some problem may occur with HTTP accelerators like Varnish. You may consider to disable it for confirmation if it generates the problem. |
SSO
|
Atlassian Crowd solution is supported.
In case of custom JIRA seraph authenticator - the result is unknown and depends on implementation. Please, contact our support if you find a problem with authenticator.
|
Epilog
Challenge
Changes made in one JIRA are isolated, they are not propagated automatically to remote JIRA instance. This delay may cause many problems and unexpected behavior and attract lot of attention and efforts to revert changes.
This section gives better understanding and described how to handle such situations.
What can change?
Connection settings - for example infrastructure changes, or password changes - what will be the symptoms in this situation? All messages will get error status, they can be retry when problem will be solved.
Contract changes - has major influence on remote JIRA instance
JIRA technical user change permission, roles or is no longer presence.
JIRA project settings can change - required fields and others
Workflow can be changed - has influence on status synchronization
More than one customfield of type Issue Status Synchronization, or Synchronized issues will be added.
What influence can those changes have on JIRA in time aspect?
Basically if we edit local contract remote JIRA still send different data so the result is invalid, even parallel change do not guarantee that data will be consistent. Possible solutions:
Block contract edition (by policy)
Make contract changes in maintain window, to be sure that no one will create issue
How to deal with changes?
When connection settings change - errors appear and all messages/communication have to be repeat on both instances
If connection will be deleted all contracts related to connection will be deleted too.
If contract changes:
If required field is no longer in mapping - an error appears, json in queue has to be changed and message has to be retry
If new field appear in contract - then is not mapped, so data are lost
If project or issue type change - all new issues will be synchronized in new issue type/project , all updates still will be made in last issutype/project. Updates are insensitive on issutype/project, they works on issue key/ issue id
If contract will be disabled/removed then updates/create messages will not be collected/ remote updates will cause errors, message processing can be repeated
If technical user change:
If user don't have permission to add/comment/attachments/update an error appears - all messages can be repeated in order to keep data synchronized
If user don't have permission to browse other changes will be collected and synchronized
If project change:
New required fields will be added, which is not in field mapping - errors appears and all messages have to be repeated
If field will be no longer in the screen changes will not be collected
If more than one customfield will be added - there will be some unexpected behaviors.